Intermediate ResultSet
1. What is intermediate result set?¶
In the SQLFlow, intermediate result set is the result set of a select statement.
The intermediate result set is used to show the details of the data flow and let you know exactly what is going on.
The intermediate result set is always built in order to create a complete data flow graph. However, you may choose to hide the intermediate result set in the UI in order to make the data flow graph cleaner in a big data flow scenario.
For example:
1 2 3 4 | |
The intermediate result set is:
1 | |

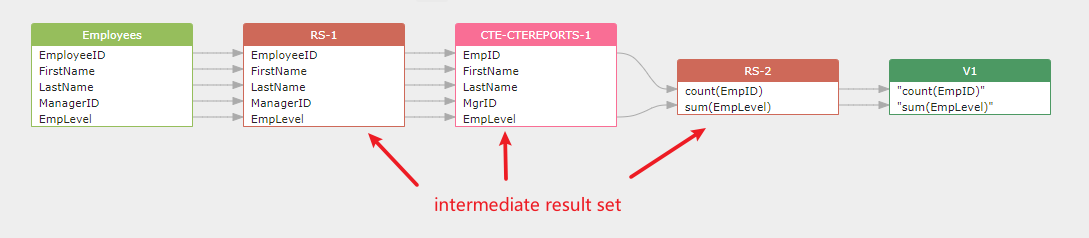
CTE example:¶
CTE will be treated as a intermediate result set.
1
2
3
4
5
6
7
8
9
10
11
12
CREATE VIEW V1 AS
WITH
cteReports (EmpID, FirstName, LastName, MgrID, EmpLevel)
AS
(
SELECT EmployeeID, FirstName, LastName, ManagerID, EmpLevel -- resultset1
FROM Employees
WHERE ManagerID IS NULL
)
SELECT
count(EmpID), sum(EmpLevel) -- resultset2
FROM cteReports
- resultset1: EmployeeID, FirstName, LastName, ManagerID, EmpLevel
- cte: cteReports (EmpID, FirstName, LastName, MgrID, EmpLevel)
- resultset2: count(EmpID), sum(EmpLevel)
And the data flow graph is like this:
2. SQL clauses that generate intermediate result set¶
1 2 3 | |
1. select list (select_list)¶
1 | |
the intermediate result set generated: (a resultset XML tag and type attribute value select_list)
1 2 3 4 5 6 7 | |
2. cte (cte)¶
CTE example SQL, the intermediate result set generated: (a resultset XML tag and type attribute value with_cte)
1 2 3 4 5 6 7 8 | |
3. set clause in update statement (update_set)¶
1 2 | |
the intermediate result set generated: (a resultset XML tag and type attribute value update-set)
1 2 3 4 | |

4. merge statement (update_select, merge_update)¶
1 2 3 4 5 6 7 8 9 | |
the intermediate result set generated: (a resultset XML tag with type attribute value merge-insert)
1 2 3 4 5 6 7 8 9 10 11 | |
5. pivot table (pivot_table)¶
1 2 3 4 5 6 7 8 9 10 11 12 | |
the intermediate result set generated: (a resultset XML tag and type attribute value pivot_table)
1 2 3 4 5 | |
6. unpivot table (unpivot_table)¶
1 2 3 4 5 6 7 8 | |
the intermediate result set generated: (a resultset XML tag and type attribute value unpivot_table)
1 2 3 4 | |
7. table alias (alias)¶
The table alias: p (empid_renamed, Q1, Q2, Q3, Q4) in the following SQL statement:
1 2 3 4 5 6 | |
the intermediate result set generated: (a resultset XML tag and type attribute value alias)
1 2 3 4 5 6 7 | |
8. array, struct, result_of, output, rs¶
Those definition of intermediate result set types are not used in the SQLFlow.
3. resultset output but not a relation¶
(1) Function¶
Due to historical design reasons, some SQL clauses will generate a result set but it is not a relation. The most common example is the SQL function that returns a scalar value.
1 | |
the intermediate result set generated: (a resultset XML tag and type attribute value scalar)
1 2 3 | |
This result is not a true intermediate result set, but rather a scalar value. However, we can distinguish it from other intermediate result sets by examining the type attribute. In this case, the type attribute has a value of function, indicating that it represents the output of a SQL function rather than a traditional result set.
This distinction is important for understanding how different SQL operations are represented in the intermediate result structure. While tables and sub-queries typically produce relational result sets, functions often return single values, which are handled differently in the data lineage analysis.
Case expression¶
case expression is treated as a special function when considered in the context of data lineage analysis.
1 2 3 4 5 6 7 8 9 10 11 | |
the intermediate result set generated: (a resultset XML tag and type attribute value case_when)
1 2 3 | |
4. List of all intermediate result sets¶
A complete list of all intermediate result sets that can be controlled to remove from the data flow graph is as follows:
- XML tag:
<resultset>, type attribute value:select_list - XML tag:
<resultset>, type attribute value:with_cte - XML tag:
<resultset>, type attribute value:update-set - XML tag:
<resultset>, type attribute value:merge-insert - XML tag:
<resultset>, type attribute value:pivot_table - XML tag:
<resultset>, type attribute value:unpivot_table - XML tag:
<resultset>, type attribute value:alias - XML tag:
<resultset>, type attribute value:function - XML tag:
<table>, type attribute value:constantTable - XML tag:
<variable>, type attribute value:variable
All default-generated <resultset> and <variable> elements can be removed by setting corresponding parameters. Elements that are not generated by default, such as <table> with the type attribute value constantTable, can be included by setting parameters as well.
Support for configuring all the above parameters has been added to the dlineage demo tool, using options like /removeResultSetXXX, /includeTableConstantTable, /removeVariable, etc.
Currently, parameters like /s, /i, /if in the dlineage demo tool are simply combinations of these individual parameters.